- 30405
- 30400
The AI-powered CDP for the world’s largest companies. Recognized as a Leader by Gartner.
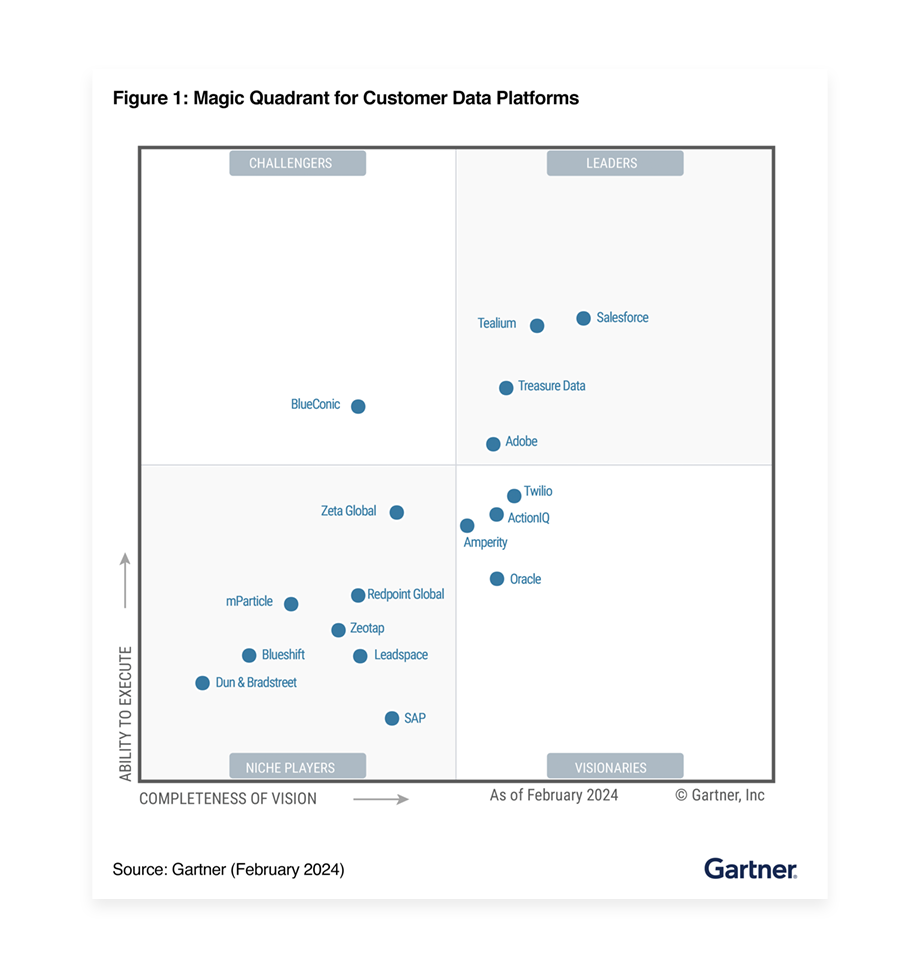
Gartner® names Treasure Data a Leader in the 2024 Magic Quadrant™ for Customer Data Platforms.
- 30398
- 30395
The AI-powered CDP for the world’s largest companies. Recognized as a Leader by Gartner.
Gartner® names Treasure Data a Leader in the 2024 Magic Quadrant™ for Customer Data Platforms.
- 30403
- 30399
The AI-powered CDP for the world’s largest companies. Recognized as a Leader by Gartner.
Gartner® names Treasure Data a Leader in the 2024 Magic Quadrant™ for Customer Data Platforms.
- 1
The AI-powered CDP for the world’s largest companies. Recognized as a Leader by Gartner.
Gartner® names Treasure Data a Leader in the 2024 Magic Quadrant™ for Customer Data Platforms.
Treasure Data empowers the world’s largest and most innovative companies to drive connected customer experiences that increase revenue and reduce costs. Built on a big data foundation of trust and scale, Treasure Data is a customer data platform (CDP) pioneer and continues to reinvent the CDP by putting AI and real-time experiences at the center of the customer journey. Our CDP gives customer-centric teams – marketing, sales, service, and more – the power to turn customer data into their greatest treasure.
Give every department the data and insights they need to increase sales and efficiency
Many companies use customer data platforms to help their marketing campaigns. But if you’re not activating customer data across every brand, on every channel, throughout the entire business, you’ve just created another data silo. We help enterprises overcome the data disconnect and give every role, whether customer facing or operations, a unified customer profile based on past interactions, real time behaviors, and AI-powered predictions.

Case Studies

Growth
38% net Income growth YOY
Shiseido, the 5th largest cosmetics maker in the world, was operating from a combination of assumptions and disparate datasets. We unified Shiseido’s 80 years of collected data and enriched it with analytics. Shiseido could now create personalized communications built around behavior and preferences. Delighting customers resulted in 38% growth year over year.

Efficiency
Saved $Millions in marketing costs
For Muji, not having enough data about customers weakened in-store sales and wasted resources on disjointed campaigns. With Treasure Data, Muji merged the physical and digital customer experiences and gave in-store customers relevant recommendations. Muji’s digital marketing got much better results: coupon redemption went up 100%, in-store revenue jumped 46%, and they saved millions in marketing costs.

Engagement
250% increase in conversion rate
Subaru collected tons of customer data, but because it was siloed, marketers relied on gut feelings and limited datasets for strategy. Now Subaru knows which customers are ready to buy. Predictive scoring and machine learning let Subaru personalize each customer experience, generating a 250% increase in conversion rate.

Loyalty
350% higher renewal rate
Treasure Data powered U.S. Soccer’s digital transformation, helping U.S. Soccer create personalized experiences at scale for their customer loyalty program members. Fans approved and U.S. Soccer saw dramatic results: renewal rates jumped from 20% to 90%, an increase of 350%.
Global Brands Need a Global Partner
Treasure Data partners with brands in more than 75 countries.

Treasure Data Delivers
Global implementation and support
With data centers, teams, and partners around the world, you’ll have efficient deployment and flexible tools everywhere you need them.
Reduced risk
Customer Data Cloud provides the security, governance, and compliance tools you need to navigate complex global privacy requirements.
End-to-end solution
Deliver connected customer experiences across every channel and every department. For all of your brands, all around the world.
How Treasure Data Helps Create Connected Customer Experiences
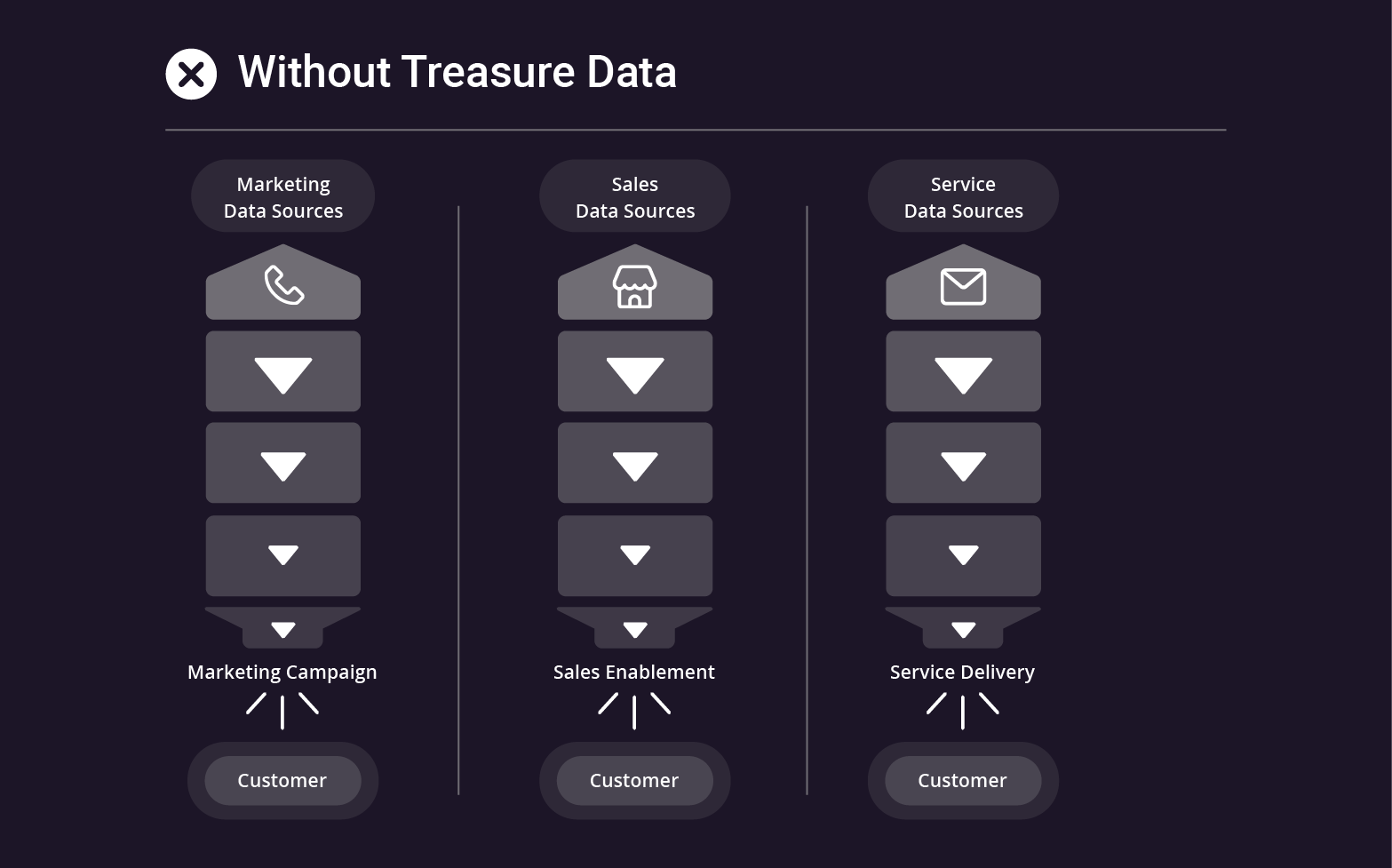
Data Silos & Assumptions
You’re collecting tons of data about your customers but you don’t ever get the full profile and teams operate in silos. Your customers don’t get the right campaigns at the right time.
Risky Data Governance
You’ve got to manage privacy and consent across channels, brands, and countries, but the process is cumbersome and the risks are high. Your IT and data teams are constantly bogged down with requests from marketing and sales.
Missed Opportunities
When departments operate from different datasets, it’s impossible to orchestrate a unified strategy. Sales, service, marketing and operations waste money and miss the mark.
Frustrated Customers
You make them repeat themselves again and again. You bombard them with ads for products they’ve already bought. They start to wonder why they should trust you with their data.
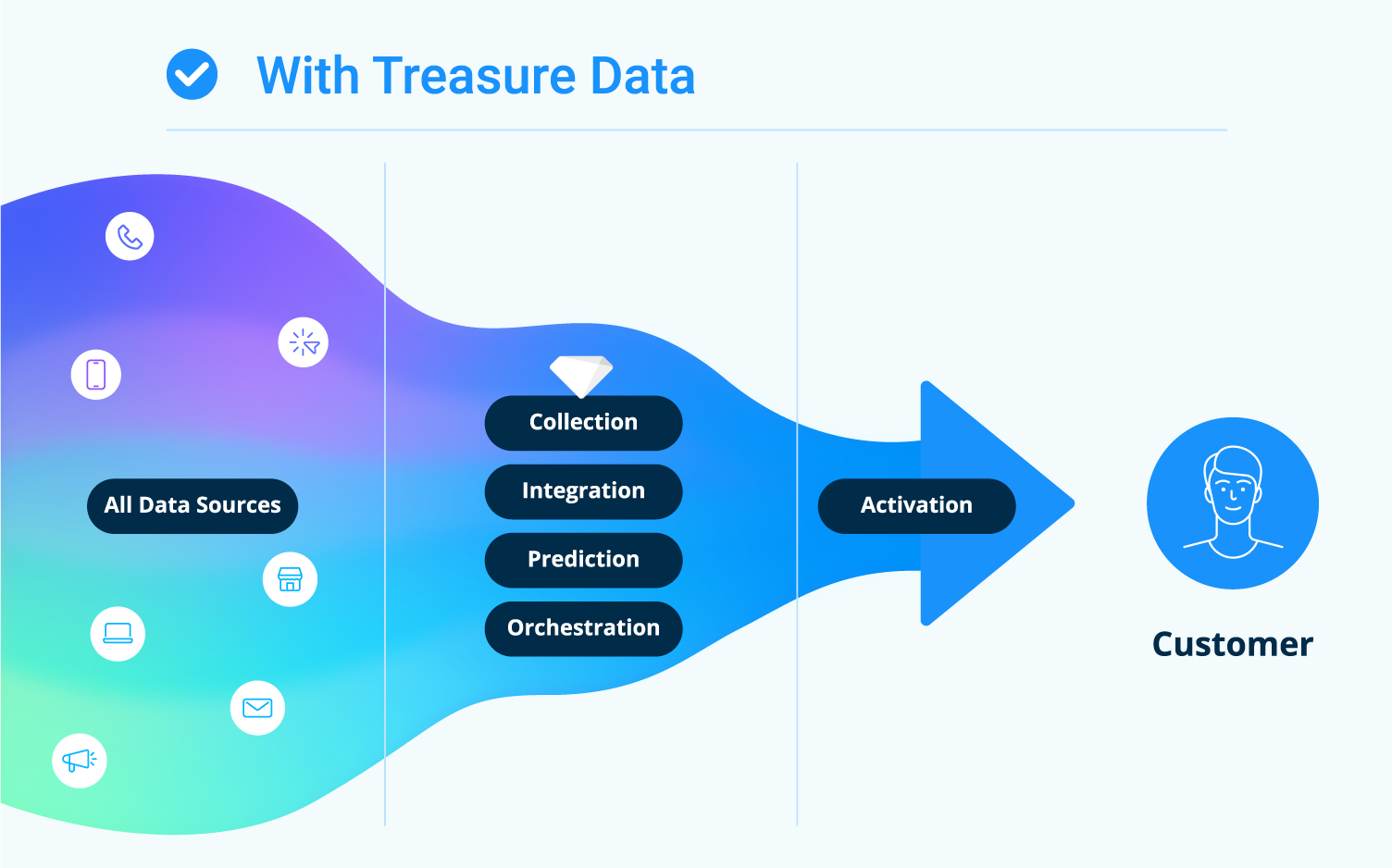
Universal Understanding
Use a single source of truth to create a connected customer experience. Know where your customers are in their journey, when they’re ready to buy, and even what future services or products they might need.
Robust Data Governance
Every part of your business operates in compliance because privacy and data governance are managed across every brand and every country. Your sales and marketing teams don’t waste IT time and resources because all customer-facing teams operate with privacy-compliant data. Your customer data is protected, and so are you.
Effective Strategies
Your teams share powerful tools that work around the world, across every channel and every brand. Because your entire organization is united around the customer, every department operates at its best, creating experiences that drive the business forward.
Engaged Customers
When you deliver connected customer experiences based on past history and current, real-time needs, you increase customer loyalty and value.
One Team, One Experience
Capture, analyze, and act on billions of customer data points. Empower every department to create a connected customer experience.
New to Enterprise CDP?
We’ve compiled resources to cover the basics and guide you through the selection process.

Create Impactful Customer Journeys
Learn how to create a great customer experience across all customer journey stages.
6 Steps to Ensure CDP RFP Success
Looking for a CDP vendor? We provided the 6 essential RFP process steps to help you find the right CDP for you business.

The Complete Guide to CDP Platforms
Everything you ever wanted to know about Customer Data Platforms (CDPs) is in this guide: How they work, CDPs in personalized marketing & CX, CDP ROI…
Don't Just Take Our Word For It
See why enterprises need Treasure Data
Treasure Data is Recognized as a CDP Leader
![]()
A Worldwide Leader in IDC MarketScape: CDP for Data and Marketing Operations Users
![]()
A Worldwide Leader in IDC MarketScape: CDP for Growth Companies
More Analyst Firms, Industry, and Customer Recognition



